当前位置: 首页 > 图文教程 > 网站运营 > 建站经验 > 图文解读Facebook 从设计原则到架构体系
- 建站经验
- 新手入门:新手建站不要痴迷免费空间
- 面临多重冲击 网址导航站将走向何方
- 适合新手参考的购买美国主机的4个误区
- 互联网商业模式的创新需要底层理论支撑
- 交换链接过程中 如何判断链接的质量
- IMG4Me.com网站在线把文字转换为图片
- 个人站长保护自己手里的域名的6个方法
- 经验分享:美国主机域名商Godaddy点评
- 如何开通在Godaddy购买域名后附送的免费空间
- 网站分析:常见的KPI评估指标知识
- 地方网站的运营和发展要结合当地实际情况展开
- 建站经验分享:建网站如何选择服务器
- 1月31日前提交真实资料到国内个大IDC商汇总
- 设计专家解析:分析下网站成本的构成
- 域名注册商Godaddy优惠:0.99美元注册或转移域名
- 个人注册域名可以获得法律保护是国际通行做法
- CN域名拥有者提交身份证扫描件有违法律
- 网站地址栏前面的小图标favicon.ico制作方法
- 篱笆网副总裁:liba.com域名解析有故障
- 影响网站转化率的4个主要原因
 建站经验 中的 图文解读Facebook 从设计原则到架构体系
建站经验 中的 图文解读Facebook 从设计原则到架构体系
出处:互联网 整理: 软晨网(RuanChen.com) 发布: 2009-10-17 浏览: 81 ::

收藏到网摘: n/a


在 QCon 2008 (旧金山站) 上Facebook 做的这个技术分享有不少值得借鉴的东西。所以,暂停对 QCon 北京的回顾,临时插播一贴。
设计原则
1尽可能的使用开源软件,并且在需要优化的时候进行优化
2Unix 哲学。包括,模块化原则;整合化原则;清晰化原则等
3任何组件具备扩展性
4最小化故障影响
5简化,简化,简化!
架构概览
Facebook 是 LAMP 的坚定支持者,也差不多是用 LAMP (或许用 LAM2P 更适合) 实现的最大的动态站点。
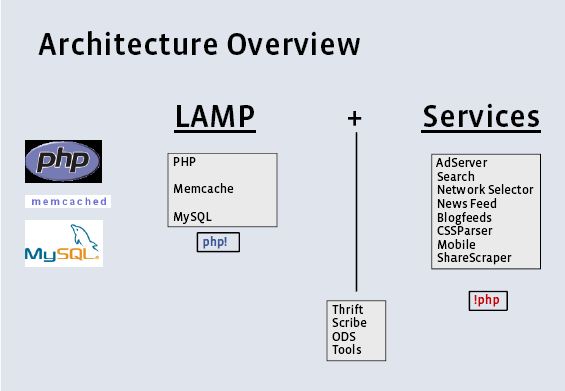
基础组件加上服务,中间用自己实现的一些工具进行粘合。其中关于运维细节的事情基本不会说出来的,这是很多公司的软实力所在。
PHP 经验
参见《Facebook 的 PHP 性能与扩展性》
MySQL 经验
1主要用于做 Key-Value 类型的存储操作,数据随机分布在多台逻辑实例上,访问多数基于全局 ID 。
2逻辑实例分散在多台物理主机上(超过1800台),负载均衡在物理层进行。
3不做读复制。
4尽量不做逻辑数据迁移(成本太高)。
5不做 JOIN 操作 (豆瓣在 QCon 上也阐述了这一点)。数据是随机分布的,关联操作反而带来了极大的复杂度。
6对于数据访问,主要的操作集中在最新的数据上,针对这部分做优化,旧的数据进行归档。
7在中心 DB 绝不存储非静态数据。
8使用服务或者 Memcached 进行全局查询。
Memcached 经验
参见我以前的笔记:Facebook 的 Memcached 扩展经验。Facebook 对 Memcached 做了不小的改进。另外,顺便说一下,前两天 Memcached 刚在 1.2.7 发布几天之后又发布了新版本 1.2.8,修正了一些问题。
一个比较有价值的是关于个人页面数据的获取的描述。这个就完全是需要做单页面 Benchmark 的细致活儿了,可能还需要产品经理能够理解工程师的“抵抗”。
1获取个人信息数据:通过Cache,隐性通过用户所在的 DB 获取(基于 User-ID 获知 DB)
2获取朋友连接信息:通过Cache,否则的话通过DB(基于 User-ID 获知 DB)
3并行抓取每个朋友的 10个照片相册 ID ,从Cache抓取,如果失效,再从 DB 抓取(基于相册 ID)
4并行抓取最近相册中的照片数据
5运行PHP 把整个业务逻辑跑出来
6返回数据给用户
然后是对 Facebook 非 LAMP 体系的东西做了一番介绍,基本上也开源了。最后参考两个架构图。
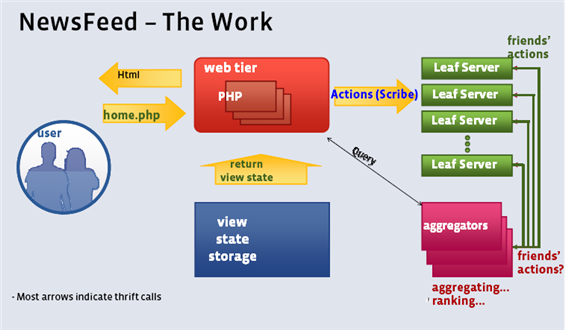
Facebook NewsFeed 的架构示意图
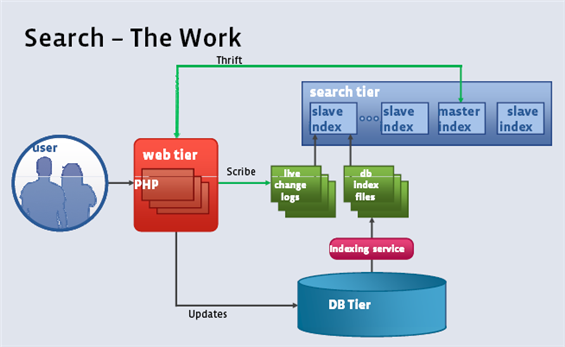
Facebook 搜索功能的架构示意图
管中窥豹,盲人摸象而已。
3) 菜单调用大分类
Sidebar做好了,下面就让菜单上显示调用的大分类,调用 《?php wp_list_cats(’include=3,4,5,6′); ?》 这句函数即可。include=ID:是我们调用的大类,多个大类的ID号用英文“,”隔开。
4) 修改category.php
现在菜单上列出的是大分类调用,这样每个大分类下面就都会显示分类列表,但如果现在有的大分类不想显示分类列表,而显示该分类的第一篇文章,就需要来修改category.php文件了。思路和修改sidebar差不多。最初 category.php的结构应该如下:
|
现在因为需要点击大分类3、5、6时,页面上展示的是文章而非分类列表,所以在 《div id= ” content ” 》《/div》里添加一个if语句:

把以前的 /*这里是调用分类的内容*/
而需要在结构中添加的是大分类3、5、6中
|
query_posts()是获取文章,其内参数可用 ’ p=文章ID ’ 或 ’ name=文章缩略名 ’ 来调用想放在大分类下首页的文章;
《h2》《/h2》里是文章名称;
the_content(); 是调用文章内容。
这样就可以在菜单中列出的大分类上点击,出来想要的文章或分类列表了。
以上几点就是企业级网站全站用WordPress搭建的大致思路。
二.注意事项
1、 这样的主题模板要基于WordPress的数据库,因为在写side时用到了分类的id号。
2、 正是因为第一条,这样的WordPress主题模板没有通用的,只能因企业而异。
3、 永久链接最好用 /%category%/%postname%/ (分类+文章缩略名)的形式,这样url地址会看起来更有结构性,看起来也更像企业或产品网站。
 评论 (0) All
评论 (0) All
